1 总体概述以及 Neo4j 简介
本博客记录如何构建一个有关陶瓷的多模态知识图谱,所使用到的数据库平台是 neo4j。Neo4j 是使用 Java 编写的一个基于图的开源数据库,随着技术的发展,人们对数据的需求已经不仅限于数据本身,更多是数据与数据之间的联系。而如果用传统的数据库来存储连接的数据,会导致遍历大量数据时不能提供合适的性能。Neo4j 遵循图数据模型,使用 cypher 语言对数据库进行操作,且具有可视化界面来直观反应数据节点之间的联系。
1.1 Mac 版本安装(Apple Silicon/Intel 通用)
安装适配 Apple Silicon 的 jdk 版本(博主安装的是 Java17)。
从 neo4j 官网下载最新安装包,博主这里安装的是 neo4j-5.5.0,https://neo4j.com/download-center/#community。
下载后解压 tar.gz 文件(尽量不要解压在下载文件夹里,最好选择一个全英文路径且没有空格的路径下),终端进入/neo4j-community-5.5.0/bin 目录下,执行neo4j start命令。如果成功执行则可以在 http://localhost:7474/browser/ 本地网站访问,显示的页面如下图则表示正常安装。
*(以下步骤为可选步骤)*将 neo4j 命令添加到系统的环境变量中,在任意目录下都可以执行neo4j start/stop等命令。
在~/.bash_profile 中加入如下命令(尖括号内容替换为你自己的路径)
1 2 export NEO4J_HOME=/Users/<username>/<your_path>/neo4j-community-5.5.0export PATH=$PATH :$NEO4J_HOME /bin
如果你使用的是 mac 自带的“终端.app”软件,则需要在~/.zshrc 的开头加入如下两行
1 2 source ~/.profileexport PATH=/opt/homebrew/bin:$PATH
保存后在终端中执行source ~/.zshrc即可生效,在~目录下执行neo4j start命令查看是否能正常启动
**恭喜你完成了 neo4j 的 mac 安装!!**🎉
2 陶瓷文物数据
2.1 数据来源——故宫博物馆网站
©️ 版权注意(转自故宫博物馆官网):任何单位或个人在以转载、引用、摘编、下载等方式使用本网站内容时,均须注明作者,并标明图片、文章的出处为“故宫博物院网站”或http://www.dpm.org.cn 。 未经故宫博物院或相关权利人的书面许可,不得修改所使用的内容。
3 使用 Neo4j 构建知识图谱
3.1 常用 Neo4j 命令
1 2 # 删除所有HAS_PROPERTY关系 match (a1:Artifact)- [r:HAS_PROPERTY]- (a2:Keywords) delete r
3.2 构建知识图谱 python 脚本
将 2.1 中收集到的数据(藏品目录)进行整理,整理成如下栏目的 csv 格式:
1 2 3 文物名称,时代,分类,窑口,文物图片url,关键词 福清窑黑釉盏,宋,结晶釉,福清窑,https://img.dpm.org.cn/Uploads/Picture/dc/21861[1024].jpg,泪痕、王安石、建窑、兔毫纹 ...
3.2.1 构建所有实体节点
构建文物节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import csvwith open ('转cypher脚本/csv文件/data2.csv' , newline='' , encoding='utf-8' ) as csvfile: reader = csv.DictReader(csvfile) cypher_statements = [] for row in reader: properties = {} if row.get('时代' ): properties['era' ] = row['时代' ] if row.get('分类' ): properties['category' ] = row['分类' ] if row.get('窑口' ): properties['kiln' ] = row['窑口' ] if row.get('文物图片url' ): properties['imageUrl' ] = row['文物图片url' ] if row.get('关键词' ): keywords = row['关键词' ].strip("[]" ).replace("'" , "" ).split(", " ) properties['keywords' ] = keywords cypher = f"CREATE (:Artifact {{name: '{row['文物名称' ]} '" if properties: property_strings = [f"{k} : {v} " if isinstance ( v, list ) else f"{k} : '{v} '" for k, v in properties.items()] cypher += ', ' + ', ' .join(property_strings) cypher += '})' cypher_statements.append(cypher) with open ('createchnew.cypher' , 'w' , encoding='utf-8' ) as cypher_file: for statement in cypher_statements: cypher_file.write(statement + '\n' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import csvwith open ('转cypher脚本/csv文件/data2.csv' , newline='' , encoding='utf-8' ) as csvfile: reader = csv.DictReader(csvfile) eras = set () categories = set () kilns = set () keywords = set () for row in reader: if row.get('时代' ): eras.add(row['时代' ]) if row.get('分类' ): categories.add(row['分类' ]) if row.get('窑口' ): kilns.add(row['窑口' ]) if row.get('关键词' ): kw = row['关键词' ].strip("[]" ).replace("'" , "" ).split(", " ) for k in kw: keywords.add(k) keyword_statements = [ f"CREATE (:Keywords {{name: '{keyword} '}})" for keyword in keywords] era_statements = [f"CREATE (:Era {{name: '{era} '}})" for era in eras] category_statements = [ f"CREATE (:Category {{name: '{category} '}})" for category in categories] kiln_statements = [f"CREATE (:Kiln {{name: '{kiln} '}})" for kiln in kilns] with open ('AllOtherNodes.cypher' , 'w' , encoding='utf-8' ) as cypher_file: for statement in keyword_statements+era_statements+category_statements+kiln_statements: cypher_file.write(statement + '\n' )
注意:上述脚本文件生成的.cypher 文件内容可以直接复制到 neo4j 浏览器中的命令行执行
3.2.2 构建所有关系
在构建关系的过程中使用到了 py2neo 工具包,可以通过如下代码来接入 neo4j 数据库并直接执行命令:
1 2 3 4 5 6 7 8 9 10 11 12 from neo4j import GraphDatabase, basic_authuri = "bolt://localhost:7687" username = "neo4j" password = "password" driver = GraphDatabase.driver(uri, auth=basic_auth(username, password)) with driver.session() as session: result = session.run("MATCH (n) RETURN count(n)" ) count = result.single()[0 ] print (f"成功连接到Neo4j数据库,当前有{count} 个节点。" )
构建“文物 - 制造时间是 - 时代”、“文物 - 采用工艺 - 分类”、“窑口 - 制造 - 文物”三个关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 with open ('data2.csv' , 'r' , encoding='utf-8' ) as f: lines = f.readlines() for line in lines[1 :]: values = line.strip().split(',' ) relic_name = values[0 ] dynasty = values[1 ] category = values[2 ] kiln = values[3 ] print (relic_name, dynasty, category, kiln) if dynasty != '' : with driver.session() as session: query = ( f"MATCH (a:Artifact {{name: '{relic_name} '}}), " f"(e:Era {{name: '{dynasty} '}}) " "MERGE (a)-[:MADE_IN]->(e)" ) session.run(query) if category != '' : with driver.session() as session: query = ( f"MATCH (a:Artifact {{name: '{relic_name} '}}), " f"(c:Category {{name: '{category} '}}) " "MERGE (a)-[:CRAFTED_WITH]->(c)" ) session.run(query) if kiln != '' : with driver.session() as session: query = ( f"MATCH (a:Artifact {{name: '{relic_name} '}}), " f"(k:Kiln {{name: '{kiln} '}}) " "MERGE (k)-[:PRODUCED]->(a)" ) session.run(query)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 with open ('csv文件/data2.csv' , newline='' , encoding='utf-8' ) as csvfile: reader = csv.DictReader(csvfile) i = 1 for line in reader: relic_name = line['文物名称' ] keywords = line['关键词' ].strip("[]" ).replace("'" , "" ).split(", " ) if keywords[0 ] != '' : print (str (i) + ': ' ) i += 1 print (keywords) with driver.session() as session: for keyword in keywords: query = ( f"MATCH (a:Artifact {{name: '{relic_name} '}}), " f"(k:Keywords {{name: '{keyword} '}}) " "MERGE (a)-[:HAS_PROPERTY]->(k)" ) session.run(query)
3.3 构建样例
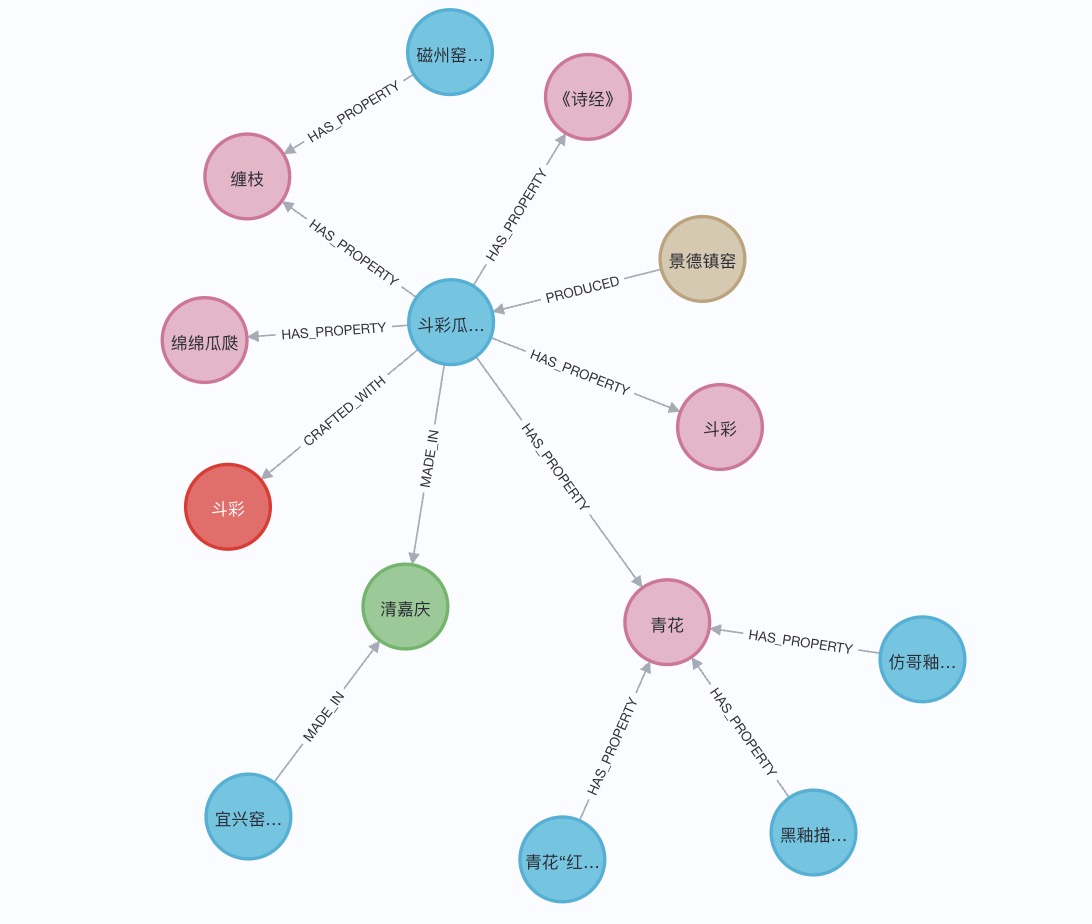
下图为 neo4j 中呈现出的部分样例,后续还需要对节点和关系进行优化和删改