
GPT训练解读

1 ChatGPT 训练原理
ChatGPT=GPT(Generative Pre-trained Transformer) + RLHF(Reinforcement Learning with Human Feedback)
ChatGPT 采用的是 InstructGPT 的架构,但选用的训练数据更多与人类聊天有关。
参考 OpenAI 发表的关于 InstructGPT 的论文:https://arxiv.org/pdf/2203.02155.pdf
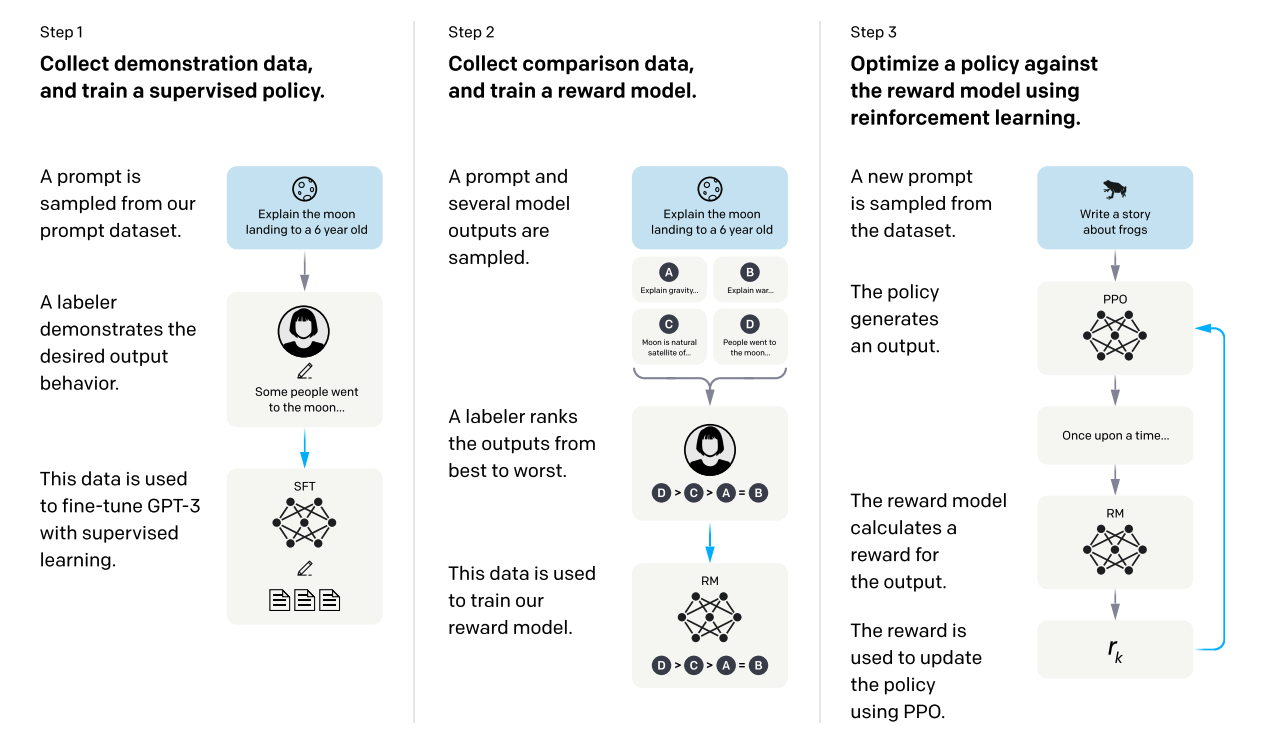
上图为 OpenAI 发表论文中对 InstructGPT 整体训练的流程,如图所示,模型训练过程分为三个阶段,分别概括如下:
- **采样和微调阶段:**训练过程的第一阶段涉及从提示库中采样和收集人类响应,即人类需要对问题进行人工回答。然后,使用 InstructGPT 工具将这些数据用于微调预训练的大型语言模型,以更好地捕捉人类偏好,得到预训练模型。但很难找到足够多的人来回答很多不同领域的问题,因此有了之后两个 step,帮助模型进一步扩充。
- **采样和训练奖励模型阶段:**在本阶段使用语言模型生成多个响应,并通过人类的偏好去手动对这些响应进行排序,训练得到一个奖励模型(Reward Model)。
- **强化学习与人类反馈阶段:**本阶段为核心阶段,在本阶段使用强化学习算法训练大型语言模型,通过强化学习中的 Proximal Policy Optimizaiton(PPO)算法引入奖励信号,生成更符合人类偏好的内容。
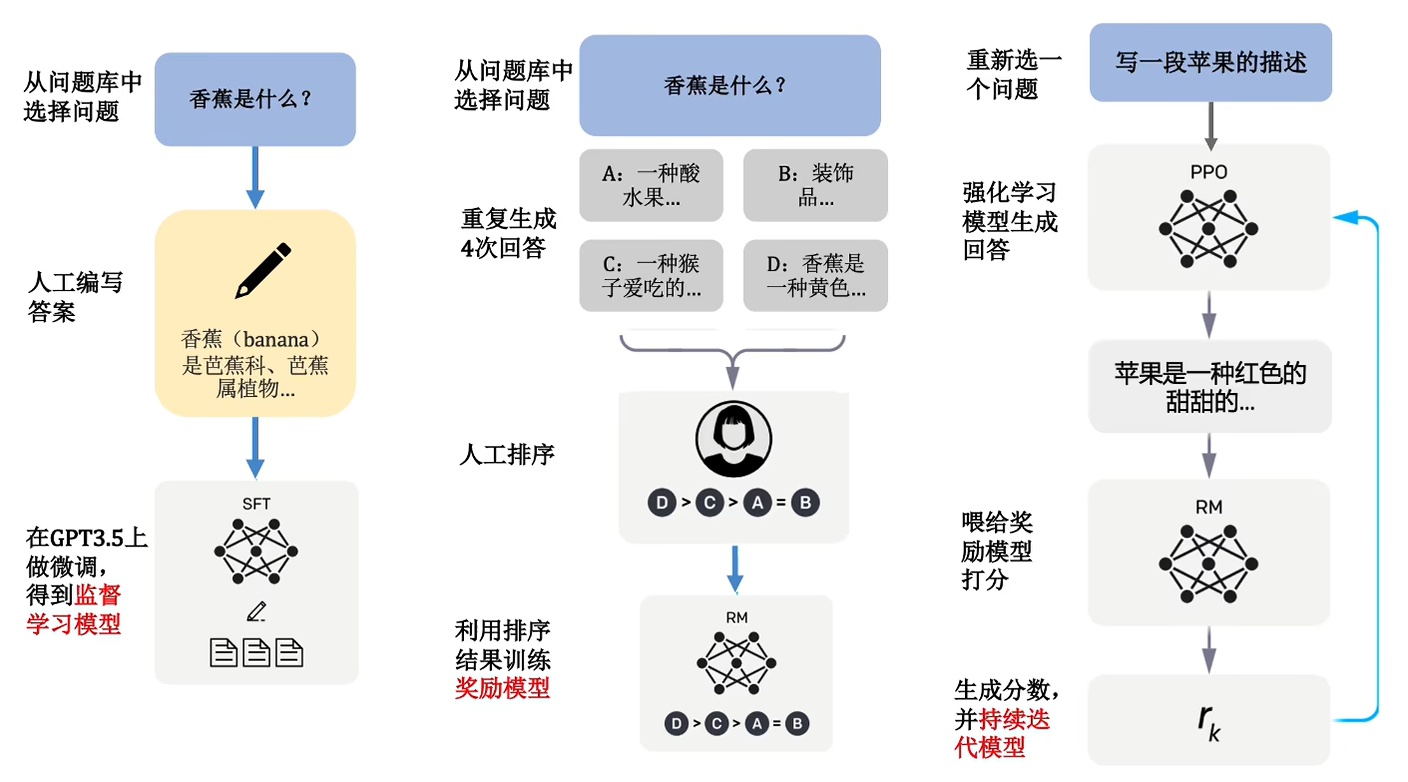
知乎上的一位老哥对上图给出了中文版本的通俗表示:
2 InstructGPT论文解读
该论文是由OpenAI发布在NIPS2022上的一篇文章,主要探讨了大语言模型可能存会产生不真实、有毒害或者对用户毫无帮助的输出,这与用户的意图并不一致。本文采取了一种训练方法(RLHF),根据人类反馈进行微调,从而使得模型与用户能在各种任务上的意图保持一致。
本文中提到的大概流程:(和第一节中一致)
- OpenAI雇佣了一个团队来标注数据,称为标注者(labelers)
- 将一些人工编写的回答和标注的数据送入OpenAI api训练监督模型的baseline(SFT, supervised fine-tuning)
- 收集模型回答并通过人工进行打分的数据,训练一个奖励模型(RM)
- 让RM作为奖励函数,使用PPO算法来对监督模型baseline进行迭代训练,得到InstructGPT
本文的主要发现如下:
- 对比GPT-3,数据标注者明显更喜欢InstructGPT
- InstructGPT 模型在真实性方面比 GPT-3 有所提高,生成真实且信息丰富的答案的频率大约是 GPT-3 的两倍。
- InstructGPT在生成有害信息方面要略好于GPT-3
- 通过修改 RLHF 微调程序来最大限度地减少公共 NLP 数据集上的性能回归。
- 模型推广到那些没有参与数据标注的标注者的偏好
- 公共的NLP数据集并不能反应InstructGPT的使用方式(在公共数据集上表现稍差,但标注者明显更喜欢InstructGPT的回答)
- InstructGPT 模型显示出对 RLHF 微调分布之外的指令的良好泛化能力(编程能力、代码解释等)
- InstructGPT仍然会出现一些简单的错误
2.1 数据集
Prompt dataset主要由OpenAI api的文本提示组成,特别是早期版本的InstructGPT有监督模型,用户使用OpenAI的playground接口访问InstructGPT时,他们的数据都可以通过循环使用来训练深度更深的模型。但是在本文中训练InstructGPT时,OpenAI对每个用户ID的可使用的Prompts限制到200个,并且对这些用户ID进行划分,分为训练集、验证集和测试集,保证测试集的数据不出现在训练集中。同时为了防止模型训练得到用户信息,OpenAI将所有的PII(Personally Identifiable Information)都过滤了出来。
最早一步针对InstructGPT的训练,标注者需要自己来编写以下三种Prompts来开启模型训练:
- 简单:标注者提出任意任务,同时确保任务需要具有多样性
- 小样本:要求标注者提出一条指令,以及该指令的多个查询/相应对
- 基于用户:在OpenAI api的候补列表中称述了很多案例,需要标注者提出与这些用例相对应的Prompts
针对这些Prompts,OpenAI在微调阶段构建了三种不同的数据集:
- SFT数据集,使用的部分是标注者标注的数据
- RM数据集,使用的部分是标注者对模型响应排序打分的数据
- PPO数据集,没有任何人类标签,用于RLHF微调的输入
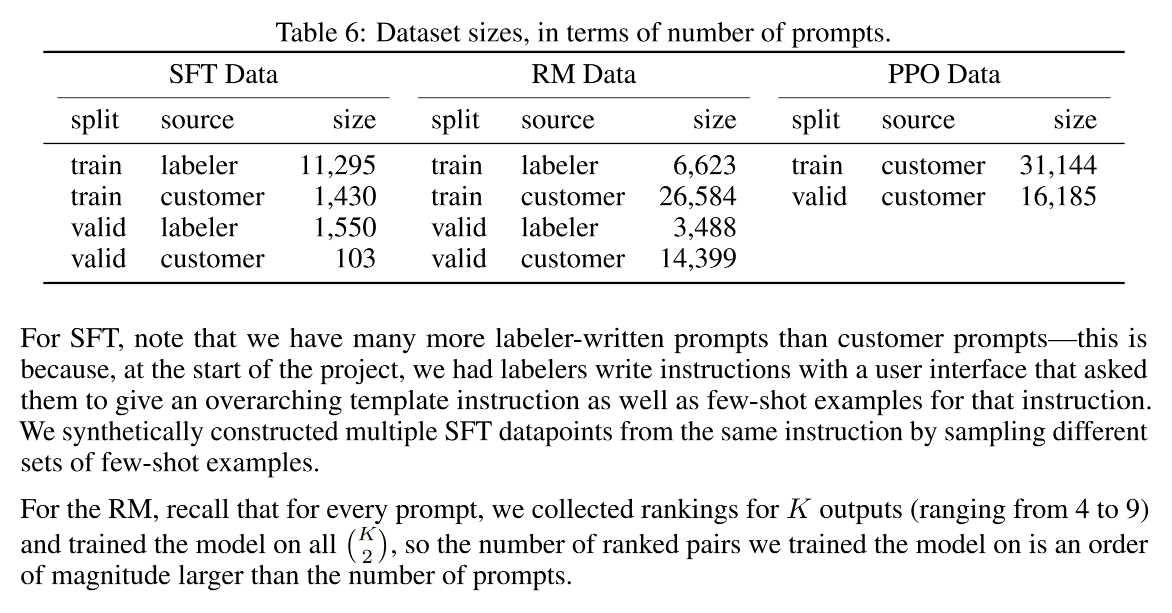
具体数据集划分见表6:
2.2 模型
本文中的InstructGPT采用GPT-3预训练模型作为baseline
- Supervised fine-tuning model(SFT): 使用监督学习训练标注者标注的数据
- Reward modeling(RM):使用训练好的SFT模型(移除SFT模型的最后一层)依据人类排序迭代对机器回答的奖励模型
- Reinforcement learning(RL):Bandit算法作为提出Prompts的环境+RM作为奖励信号,使用PPO算法进行迭代
2.3 评估方法
对于模型的“诚实性”评估:模型编造事实的趋势+TruthfulQA dataset
对于模型的“有害性”评估:标注者人工评估+benchmark测试(RealToxicityPrompts + CrowS-Pairs)
OpenAI将模型的定量评估总结为两个部分:API分发评估+公共NLP数据集评估
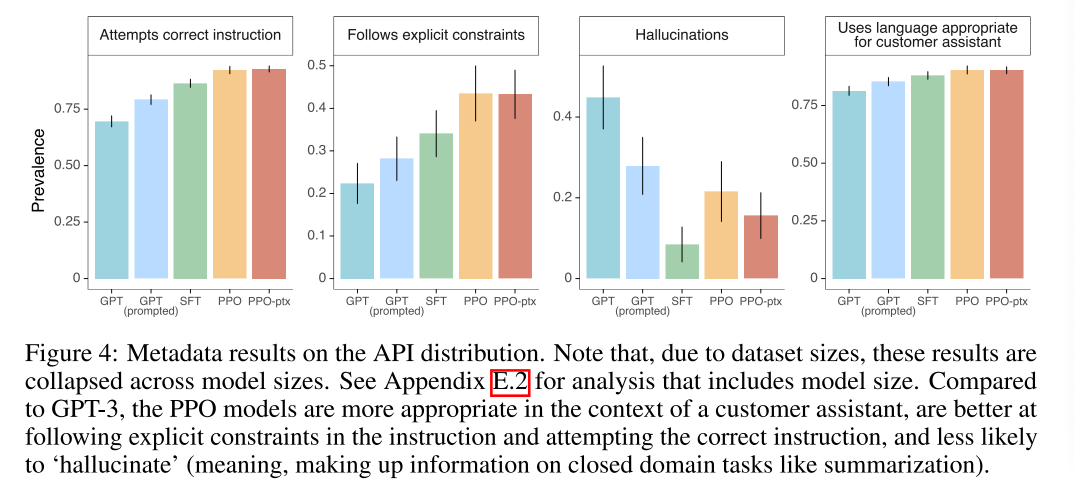
2.4 实验结果
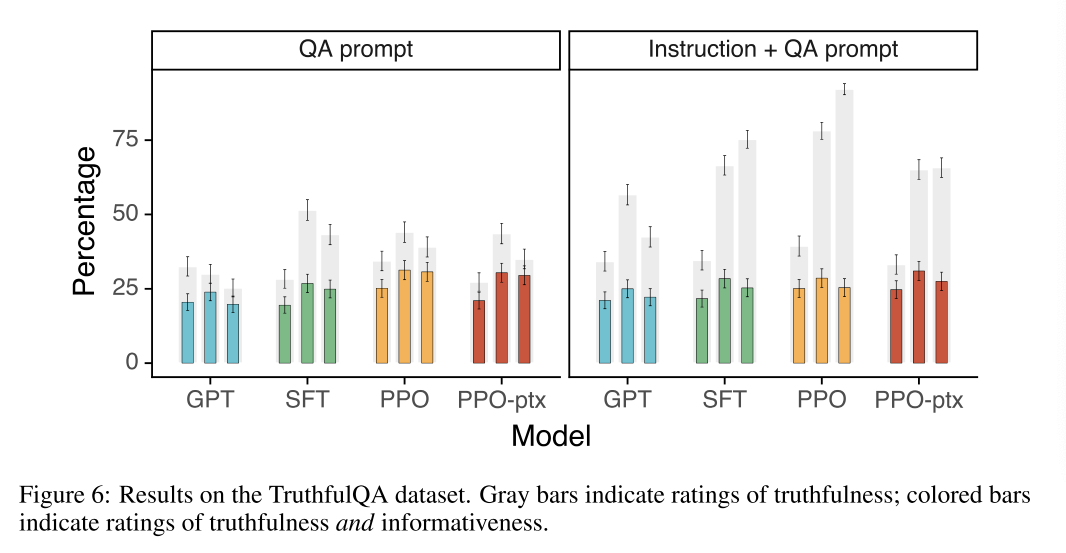
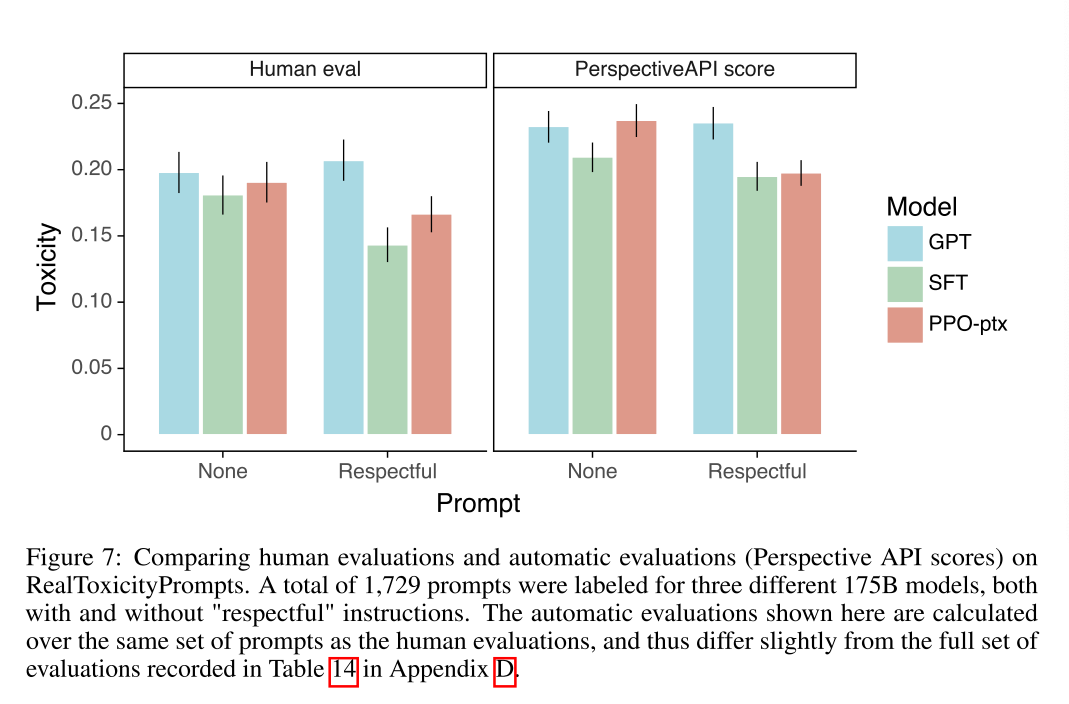
参考文章
- Title: GPT训练解读
- Author: Cyria7
- Created at : 2023-08-30 22:38:22
- Updated at : 2024-03-24 10:09:12
- Link: https://cyria7.github.io/2023/08/30/rlhf/
- License: This work is licensed under CC BY-NC-SA 4.0.