
大模型方向文献阅读记录

1 经典文献&综述
本人可能大模型研究方向研究整理:
- 研究大模型在语音输入的情况下是否能分辨出语音语调区别对整句语言表达重点、表达含义区别的问题。
- 研究大模型在parataxis(意合,中文)和hypotaxis(形合,英语)方向上的训练数据是否会导致模型效果的不同?
- 关注大模型在小算力情况下的性能优化,即研究小算力可训练的大模型。
📒GPT-4 Technical Report
文献地址:https://cdn.openai.com/papers/gpt-4.pdf
发布时间:2023-03-27
文献分类:大模型最新进展报告
简述:
GPT-4是一种大规模的多模态模型。GPT-4在各种专业和学术基准测试上表现出人类水平。GPT-4是一个基于Transformer的模型,通过预测文档中的下一个标识符(Token)的形式进行预训练。训练后的对齐(alignment)过程导致了模型回答的真实性和对指令的遵循程度有了提升。该项目的核心组件是开发基础架构和优化方法,这些方法在各种规模上都是可预测的。这使得我们能够准确地在部分方面预测GPT-4的性能,训练的模型是一个计算不超过 GPT-4计算量的1/000的模型。
读书笔记:
- Predictable Scaling:能够在训练时,其表现能够提前预测。OpenAI通过训练1000x及更小的模型,通过这些模型的表现来预测GPT-4训练的最终的loss以及一些任务上的pass rate等指标。但也存在例外情况。相关工作(Auto-scaling Vision Transformers without Training, https://openreview.net/forum?id=H94a1_Pyr-6)。
- 本论文不牵涉到任何模型架构、硬件、训练计算、数据集构建、训练方法等详细信息。
- GPT-4在学术和专业考试上是否使用RLHF过程对实验结果的影响并不是很大(Table 1&Figure 4)。
- GPT-4在传统大语言模型的benchmark上要大大优于现有的语言模型(Table 2)。
- 在MMLU数据集的不同语言版本上,GPT-4在英语上的准确率达到了85%,在普通话上为80%,对于部分小语种如Latvian也能够有较高准确率,但存在部分语言准确率在75%以下。
- GPT-4可以接受视觉输入+文本输入,这样的输入和单纯的文字输入是同级的。
- GPT-4并不是完全准确的,也会产生“幻觉”类信息.
本文相关信息整理:
- MMLU基准测试(Massive Multitask Language Understanding,大规模多任务语言理解):旨在通过仅在零样本和少样本设置下评估模型来衡量预训练 期间获得的知识。
大模型排行榜:https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
专栏文章:https://blog.csdn.net/qq_41185868/article/details/131137555 - OpenAI Evals: https://github.com/openai/evals
📒Attention Is All You Need
文献地址:https://arxiv.org/abs/1706.03762
发布时间:2017-06-12
文献分类:Transformer、大模型基础
简述:
Transformer完全基于注意力机制,无需递归和卷积。Transformer是第一个完全基于注意力的序列转换模型,用多头自我注意力取代了编码器-解码器架构中最常用的递归层。在翻译任务中,Transformer的训练速度明显快于基于递归层或卷积层的架构。
详细模型解释可以看“本文信息整理”中的知乎专栏。
模型架构:
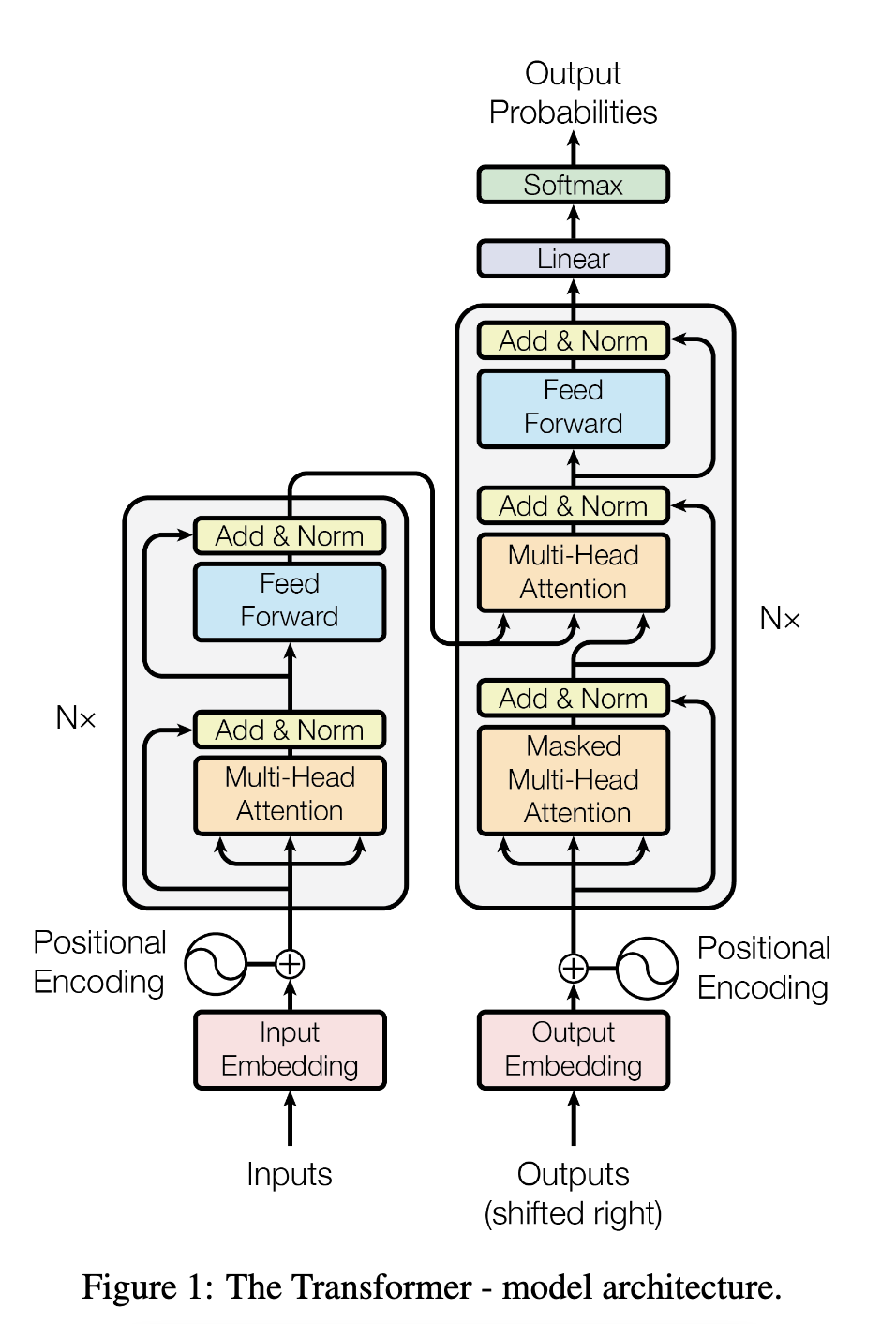
Atention计算详解:
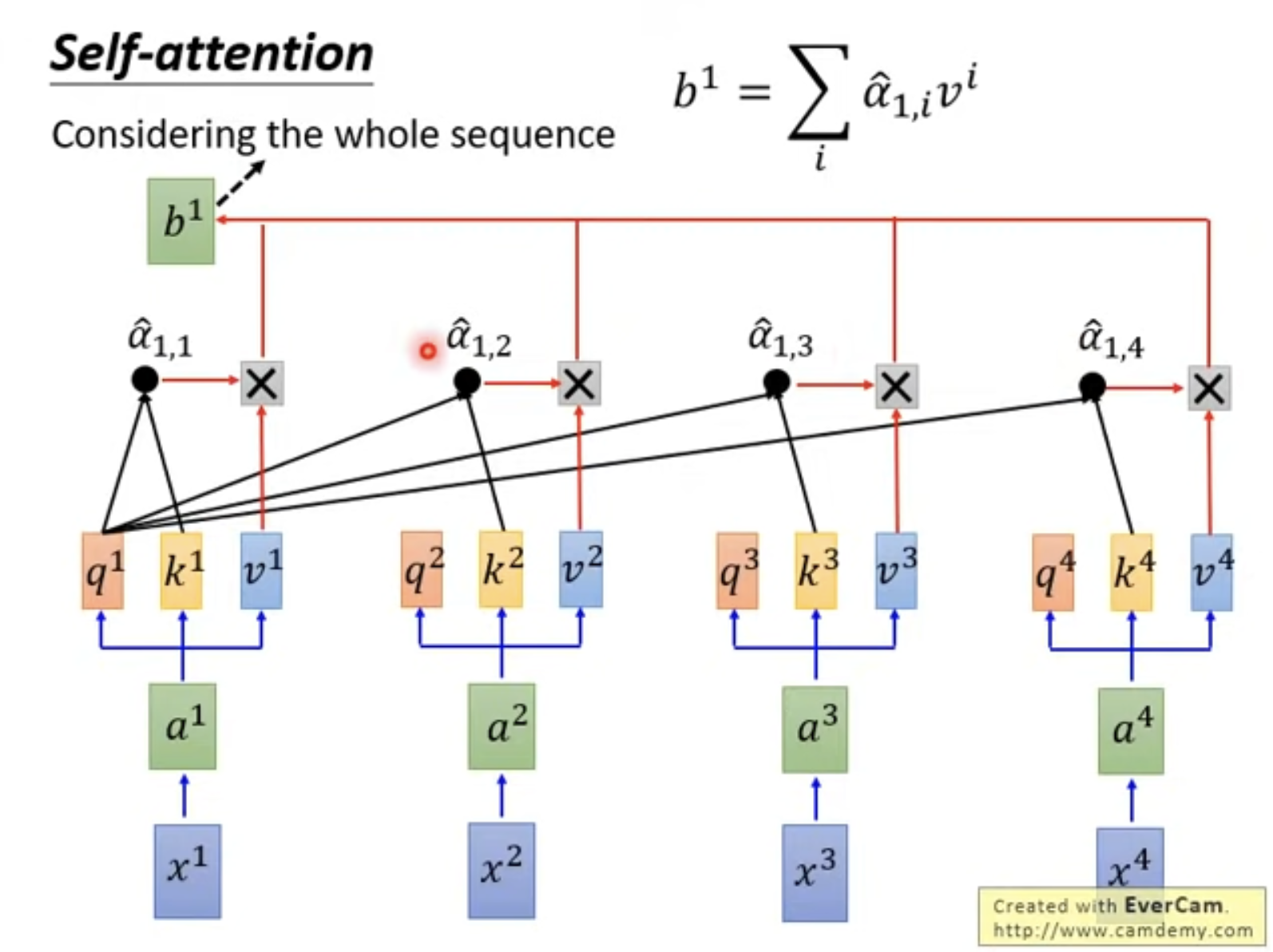
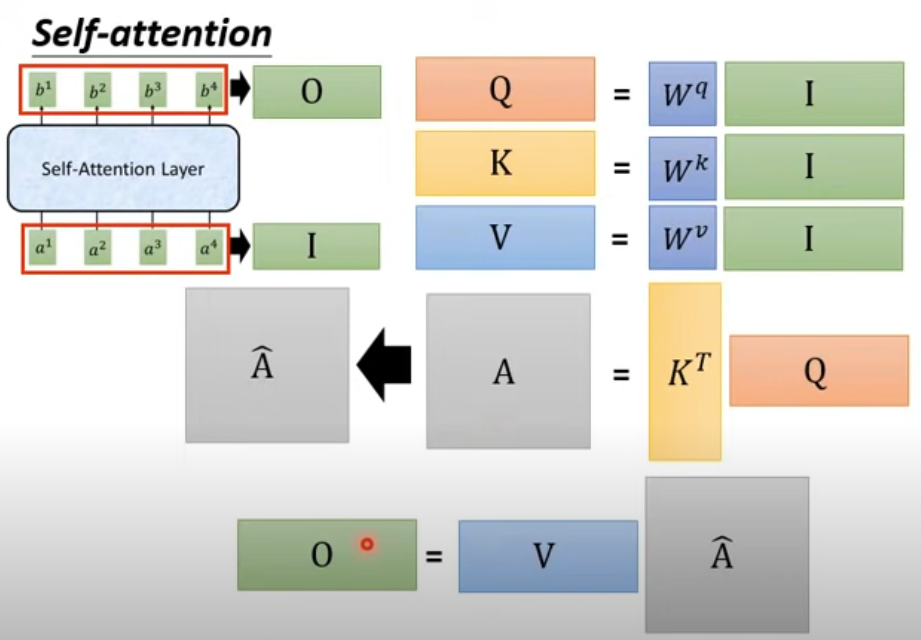
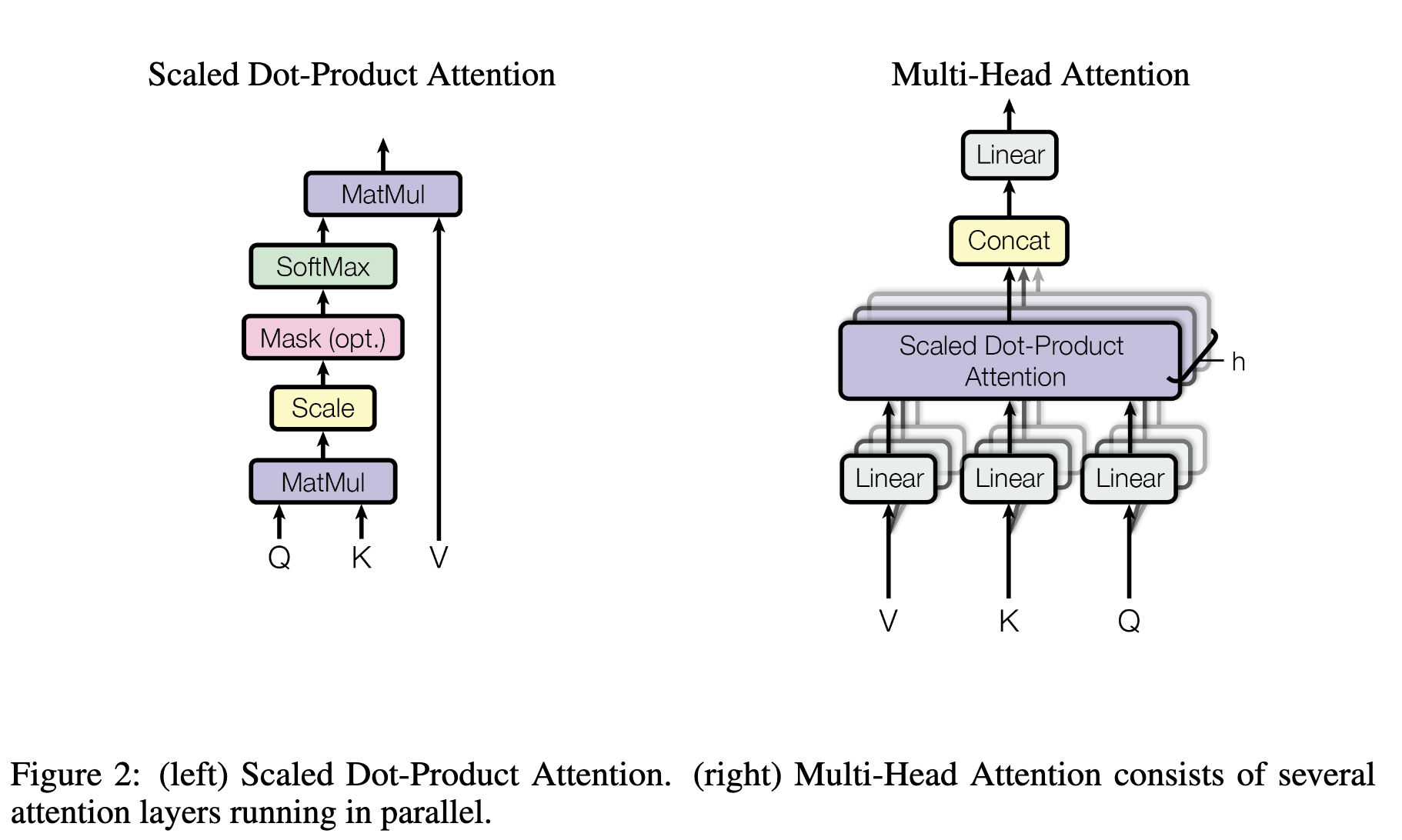
其中Multi-Head Attention结构如下:
本文信息整理:
- 李宏毅讲transformer:https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=60
- 知乎专栏:https://zhuanlan.zhihu.com/p/338817680
📒Deep Reinforcement Learning From Human Preferences
文献地址:https://arxiv.org/abs/1706.03741
发布时间:2017-06-12
文献分类:大模型基础、RLHF
简述:
在本文之前取得较为成功,将强化学习扩展到大型问题的案例都是在明确指定回报函数的领域(如AlphaGo)。但现实中多数任务涉及的目标都很复杂、定义不清或难以明确,在复杂的强化学习系统中,人为指定汇报较为困难。本文探索了人类对每对轨迹片段偏好进行定义的目标,结果表明,尽管人类提供的反馈数目比智能体与环境交互总数的1%还要少,但可以有效的在不适用奖励函数的情况下解决复杂的RL问题。
读书笔记:
- 作者在这篇论文中只让人类去判断智能体轨迹的好坏,而无需反馈每个动作的回报函数,大大降低了人类的劳动强度和对人类反馈的要求,结果证明只需要少量的人类反馈,就能实现较好的效果。
- 核心贡献是偏好学习和深度强化学习结合。
- 选择轨迹片段给人类进行偏好标注。
- 深度神经网络的参数更新过程。
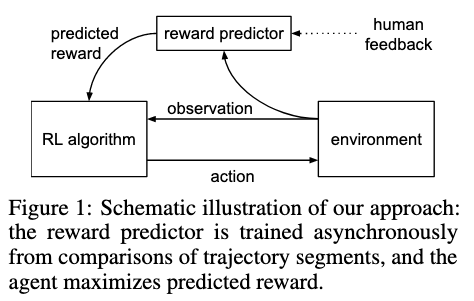
本文信息整理:
📒A Survey of Large Language Models
文献地址:https://arxiv.org/abs/2303.18223
发布时间:2023-09(持续更新)
文献分类:大模型综述
读书笔记:
- GPT技术演进介绍。
- 大语言模型资源整理:公开、非公开模型检查点或API;常用语料库;常用代码库。
- 大语言模型的训练与微调。
- LLM能力测评任务的整理与汇总。
- 大模型未来方向展望。
📒A Survey on Mutimodal Large Language Models
文献地址:https://arxiv.org/abs/2306.13549
发布时间:2023-12(持续更新)
文献分类:多模态、综述
项目地址:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models?tab=readme-ov-file
读书笔记:
- 多模态指令调整(M-IT):提高多模态模型的Zero-shot能力
- 模态桥接:LLavA / Flamingo / BLIP-2 / 专家模型
- 数据:benchmark adaption(VQA) / self-instruction(LLaVA / GPT4-Tools / …)
- 验证:Closed-set / Open-set
- 多模态上下文学习(M-ICL, Mutimodal In-Context Learning):解决各种视觉推理任务,教LLM使用外部工具
- 多模态思维连(M-CoT):多模态桥接、学习范式、链结构、生成模态
- LLM辅助视觉推理(LAVR)
本文信息整理:
2 大模型调优
📒GPT Understands, Too(P-Tuning v1)
文献地址:https://arxiv.org/abs/2103.10385
发布时间:2021-03-18
文献分类:大模型调优
读书笔记:
- P-Tuning是一种连续可微的virtual token,即将Prompt转化为可以学习的embedding层。
- 使用LSTM+MLP来编码这种virtua token,再输入到模型。
- 在LAMA和SuperGLUE两个数据集上取得了非常好的效果。
📒QLoRA: Efficient Finetuning of Quantized LLMs
文献地址:https://export.arxiv.org/pdf/2305.14314v1.pdf
发布时间:2023-05-23
文献分类:大模型微调、小内存方法
读书笔记:
- QLORA是一种用高效微调方法,使得能在一个48GB的GPU上微调一个65B的参数模型,同时保留16位微调任务性能。
- 在Vicuna基准上超过了之前公开发布的所有模型,在只需要24h微调且在一个GPU的情况下,达到了ChatGPT性能水平的99.3%。
- 引入4位NormalFloat数据类型,是信息论中最适合正态分布权重的新数据类型;双倍量化,通过将量化常数来减少平均内存占用;页式优化器,用于管理内存峰值。
本文信息整理:
📒LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
文献地址:https://arxiv.org/abs/2106.09685
发布时间:2021-10
文献分类:大模型微调、小内存方法
读书笔记:
- 该方法的核心思想是通过低秩分解来模拟参数的该变量,从而以极小的参数量来实现大模型的间接训练。
3 最新前沿进展
📒Self-Supervised Hypergraph Transformer for Recommender Systems
文献地址:https://arxiv.org/abs/2207.14338
发布会刊:KDD2022
文献分类:Transformer新架构
文章摘要:
文章《Self-Supervised Hypergraph Transformer for Recommender Systems》的摘要部分指出,图神经网络(GNN)在以用户-物品互动图为基础的协同过滤中显示出了前景。然而,现有的推荐模型大多依赖于高质量的训练数据,而在许多实际推荐场景中,用户行为数据通常嘈杂且分布不均。针对这一问题,本文提出了一种新颖的自监督超图变换器框架(SHT),该框架通过探索全局协作关系以显式方式增强用户表示。具体来说,首先通过超图变换器网络使图神经协同过滤范式能够维护用户和物品之间的全局协作效应。通过提炼的全局上下文,提出了一种跨视图生成式自监督学习组件,用于用户-物品交互图上的数据增强,以增强推荐系统的鲁棒性。广泛的实验表明,SHT在各种最新基准测试中的性能显著提高。进一步的消融实验表明,我们的SHT推荐框架在减轻数据稀疏和噪声问题方面具有优越的表现能力。
读书笔记:
- 本文提出了一种自监督超图变换器架构(SHT),该框架通过探索全局协作关系以显示方式增强用户表示。
本文信息整理:
- topology-aware Transformer
- 知乎专栏:https://zhuanlan.zhihu.com/p/587800505
- 搜狐文章:https://www.sohu.com/a/585891595_121119001
📝专栏:GPT-4有情商!CAS && 微软 | 提出 EmotionPrompt,可使其性能提升10.9%!
专栏地址:https://zhuanlan.zhihu.com/p/665655912
文献地址:https://arxiv.org/pdf/2307.11760.pdf
发布时间:2023-11-12
专栏分类:情感增强
读书笔记:
- 情商是复杂的人类属性之一,人类的情商肯定会对人类的行为产生影响。在决策领域,有研究强调了情绪在引导注意力、学术界和竞技体育领域中的重要性。
- 本文提出了EmotionalPrompt:将情感刺激融入到原始Prompt中。
- 研究结果表明LLM具有情商,并且可以通过情绪刺激来增强,在表现、诚实度和责任指标方面平均能够提高10.9%
- Title: 大模型方向文献阅读记录
- Author: Cyria7
- Created at : 2023-11-22 13:16:02
- Updated at : 2024-01-06 13:26:10
- Link: https://cyria7.github.io/2023/11/22/readpapers/
- License: This work is licensed under CC BY-NC-SA 4.0.